Portfolio management
Generalidades
La teoría de la fijación de precios de derivados es una teoría de rendimientos deterministas: cubrimos nuestros derivados con el subyacente para eliminar el riesgo, y nuestra cartera libre de riesgo resultante gana la tasa de interés libre de riesgo. Los bancos ganan dinero con este proceso de cobertura; venden algo por un poco más de lo que vale y cubrir el riesgo para obtener una ganancia garantizada. Los gestores de fondos compran y venden activos (incluidos los derivados) con el objetivo de superar la tasa de rendimiento del banco. Al hacerlo, se arriesgan. En este artículo explico algunas de la teorías detrás del riesgo y la recompensa de la inversión y, como optimizar una cartera para obtener el mejor valor por dinero.
Diversificación
Introduciremos algo de notación y muestro el efecto de la diversificación sobre la rentabilidad de la cartera. Supongamos que tenemos una cartera de \(N\) activos. El valor hoy del i-ésimo activo es \(S_i\) y su rendimiento aleatorio es \(R_i\) sobre nuestro horizonte de tiempo \(T\). Las \(R_i \sim N(\mu_iT, \sigma_i\sqrt{T})\). La correlación entre los rendimientos de la i-ésima y j-ésimo activo es \(\rho_{ij}\) (con \(\rho_{ii} = 1\)).
Los parámetros \(\mu, \sigma\) y \(\rho\) corresponden a la media, volatilidad y correlación a la que estamos acostumbrados. Tenga en cuenta la escala con el horizonte de tiempo.
Si tenemos \(w_i\) del i-ésimo activo, entonces nuestra cartera tiene valor
\[ \Pi = \sum_{i=1}^{N} w_iS_i \]
Al final de nuestro horizonte temporal, el valor es
\[\Pi + \delta\Pi = \sum_{i=1}^{N} w_iS_i(1+R_i)\]
Podemos escribir el cambio relativo en el valor de la cartera como
\[ \frac{\delta\Pi}{\Pi} = \sum_{i=1}^N W_iR_i\hspace{1.5cm} (1) \]
donde
\[ W_i = \frac{w_iS_i}{\sum_{i=1}^N w_iS_i} \]
Los pesos \(W_i\) suman uno.
A partir de (1) es sencillo calcular el rendimiento esperado de la cartera
\[ \mu_{\Pi} = \frac{1}{T}E\left[\begin{array}{c}\frac{\delta\Pi}{\Pi}\end{array}\right] = \sum_{i=1}^{N}W_i \mu_i\hspace{6cm} (2) \]
Y la desviación estándar de los retornos son
\[ \sigma_{\Pi} = \frac{1}{\sqrt{T}}\sqrt{var\left[\begin{array}{0} \frac{\delta \Pi}{\Pi}\end{array}\right]} = \sqrt{\sum_{i=1}^{N}\sum_{j=1}^N W_iW_j \rho_{ij}\sigma_i\sigma_j}\hspace{1.5cm} (3) \]
En ellos hemos relacionado los parámetros de los activos individuales con la rentabilidad esperada y la desviación estándar de toda la cartera.
Supongamos que tenemos activos en nuestra cartera que no están correlacionados, es decir, \(\rho_{ij} = 0\), \(i = j\). Para simplificar las cosas, suponga que tienen el mismo peso, de modo que \(W_i = \frac{1}{N}\). El rendimiento esperado de la cartera está representado por
\[ \mu_{\Pi} = \frac{1}{N}\sum_{i=1}^N \mu_i \]
El promedio de los rendimientos esperados de todos los activos, y la volatilidad se convierte en
\[ \sigma_{\Pi} = \sqrt{\frac{1}{N^2}\sum_{i=1}^N \sigma_i^2} \]
Esta volatilidad es \(O(N^{-1/2})\) ya que hay \(N\) términos en la suma. A medida que aumentamos el número de activos en cartera, la desviación estándar de los rendimientos tiende a cero.
Supongamos que todos los activos no están correlacionados, pero veremos algo similar cuando describa el Modelo de fijación de precios de activos de capital; la diversificación reduce la volatilidad sin perjudicar las expectativas de rendimientos.
Ahora me voy a referir a la volatilidad o desviación estándar como riesgo, algo malo que debe evitarse (dentro de lo razonable), y el rendimiento esperado como recompensa, algo bueno que queremos tanto como sea posible.
Teoría Moderna del Portafolio
Pödemos usar el marco anterior para discutir la “mejor” cartera. La definición de “mejor” fue abordada con mucho éxito por el Premio Nobel Harry Markowitz. Su modelo proporciona una manera de definir carteras que sean eficientes.
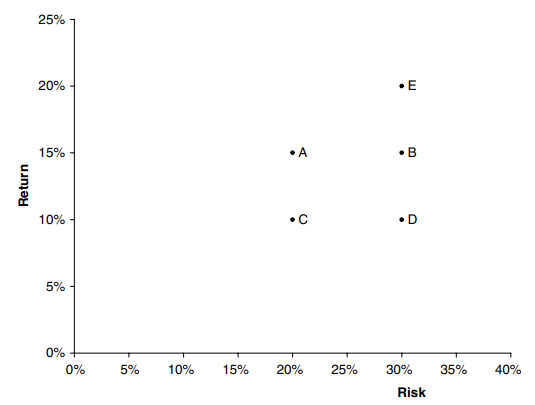
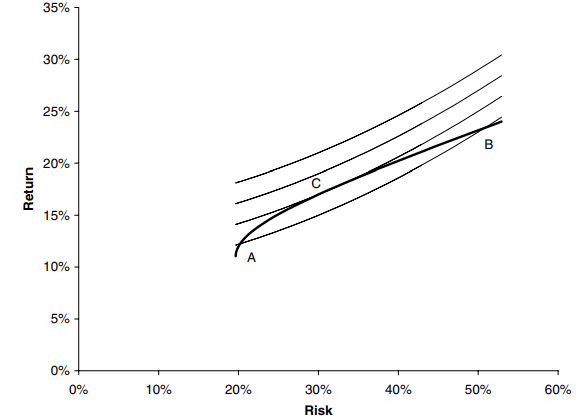
Una cartera eficiente es aquella que tiene la recompensa más alta para un nivel de riesgo, o el riesgo más bajo para una recompensa dada. Para ver cómo funciona esto imagina que hay cuatro activos en el mundo \(A, B, C\) y \(D\) con recompensa y riesgo como se muestra en la figura 1 (ignore E por el momento). Si pudieras comprar alguno de estos (pero de momentos no te permiten más de uno), ¿cuál comprarías? eliges D? No, porque tiene el mismo riesgo que B pero menos recompensa, tiene la misma recompensa que como C pero pun mayor riesgo. Entonces, podemos descartar \(D\). ¿Qué pasa con B o C? Ambos son atractivos cuando se comparan con D, pero entre si no estan claro, B tiene un mayor riesgo, pero obtiene una mayor recompensa. Sin embargo, comparándolos a ambos con A vemos que no hay competencia, ya que A es la elección preferida. Si introducimos el activo E con el mismo riesgo que B y una recompensa mayor que A, entonces no podemos decir objetivamente cuál de A y E es mejor; esta es una elección subjetiva y depende de las preferencias de riesgo de un inversor.
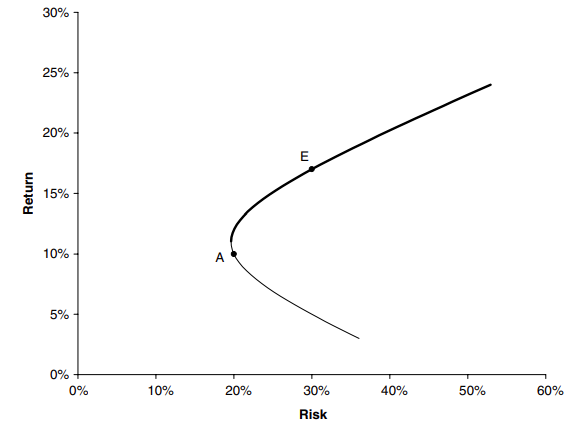
Ahora suponga que tengo los dos activos A y E de la figura 2, y puedo combinar en mi cartera, ¿qué efecto tiene esto en mi riesgo/recompensa?
De (2) y (3) tenemos
\[\mu_{\Pi} = W\mu_{A} + (1-W)\mu_{E}\]
y
\[ \sigma_{\Pi}^2 = W^2\sigma_{A}^2 + 2W(1-W)\rho\sigma_{A}\sigma_{E} + (1-W)^2\sigma_{E}^2 \]
Aquí \(w\) es el peso del activo A y, recordando que los pesos deben sumar uno, el peso del activo E es \(1 - E\).
A medida que variamos W, también cambian el riesgo y la recompensa. La linea en el espacio de riesgo/recompensa que es parametrizada por W es una hipérbola, como se muestra en la figura 2. La parte de esta curva en negrita es eficiente, y es preferible al resto de la curva. Una ves más, las preferencias de riesgo de un individuo dirá dónde quiere estar en la curva audaz. Cuando una de las volatilidades es cero la línea se vuelvve recta. en cualquier lugar de la curva entre los dos puntos se requiere una posición larga en cada activo. Fuera de esta región, uno de los activos se vende al descubierto para financiar la compra del otro. Todo lo que sigue asume que podemos vender al descubierto tanto activo como queramos. Los resultados cambian ligeramente cuando hay restricciones.
Si tenemos muchos activos en nuestra cartera, ya no tenemos una simple hipérbola para nuestros posibles perfiles de riesgo/recompensa; en cambio obtenemos algo como lo que se muestra en la Figura 3.
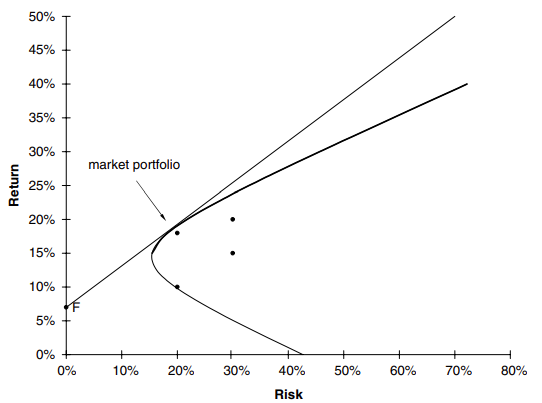
Esta figura ahora usa todo A, B, C, D y E, no solo A y E. Aunque B, C y D no son individualmente atractivos, bien pueden ser útiles en un portafolio, dependiendo de como se correlacionen, o no, con otras inversiones. En esta figura podemos ver la frontera eficiente marcada en negrita. Dado cualquier elección de cartera elegiríamos tener una que se encuentre en esta frontera eficiente.
Incluir una inversión sin riesgo
Una inversión sin riesgo que gana una tasa de rendimiento garantizada \(r\) sería el punto F en la Figura 3. Si se nos permite mantener este activo en nuestra cartera, dado que la volatilidad de este activo es cero, obtenemos la nueva frontera eficiente que es la línea recta en la Figura 3. El portafolio para el que la línea recta toca la frontera eficiente original se denomina cartera de mercado. La linea recta en sí misma se llama la línea del mercado de capitales.
Donde quiero estar en la frontera eficiente?
Habiendo encontrado la frontera eficiente, queremos aber dónde debemos estar. Esta es una elección personal, la frontera eficiente es objetiva, dados los datos, pero la “mejor” posición en ella es subjetiva.
La siguiente es una forma de interpretar el diagrama de riesgo/recompensa que puede ser útil en la elección de la mejor cartera.
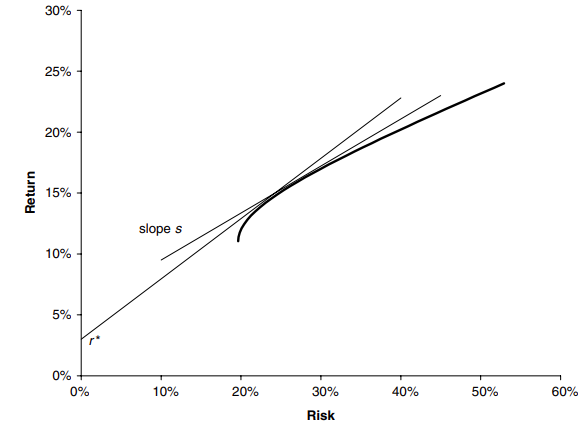
El rendimiento de la cartera se distribuye normalmente porque está compuesto por activos que se distribuyen normalmente. Tiene media \(\mu\) y desviación estándar \(\sigma\) (he ignorado la dependencia del horizonte T). La pendiente de la línea que une la cartera con el activo libre de riesgo es
\[ s = \frac{\mu_{\Pi} - r}{\sigma_{\Pi}} \]
Esta es una cantidad importante; es una medida de la probabilidad de tenter un rendimiento que exceda r. Si \(C(.)\) es la función acumulada para la distribución normal estandarizada, entonces \(C(s)\) es la probabilidad de que el rendimiento en \(\Pi\) sea al menos q \(r\). Mas generalmente
\[ C\left(\begin{array}{0}\frac{\mu_{\Pi} - r^*}{\sigma_{\Pi}}\end{array}\right) \]
es la probabilidad de que el rendimiento exceda \(r^*\). Esto sugiere que si queremos minimizar la posibilidad de una rentabilidad inferior a \(r^*\) debemos elegir la cartera del conjunto de fronteras eficientes, \(\Pi_{eff}\) con el mayor valor de la pendiente
\[ \frac{\mu_{\Pi_{eff}} - r^*}{\sigma_{\Pi_{eff}}} \]
Por el contrario, si mantenemos la pendiente de esta línea fija en \(s\), entonces podemos decir que con una confianza de \(C(s)\) no perderemos más que
\[ \mu_{\Pi_{eff}} - s\sigma_{\Pi_{eff}} \]
Nuestra elección de cartera podría determinarse maximizando esta cantidad. Estas dos estrategías se muestran esquemáticamente en la Figura 5.
Ninguno de estos métodos da resultados satisfactorios cuando existe inversión libre de riesgo entre los activos y hay ventas cortas sin restricciones, ya que dan como resultado un endeudamiento infinito.
Otra forma de elegir la cartera óptima es con la ayuda de una función de utilidad. Este enfoque es popular entre los economistas. En la Figura 6 muestro las curvas de indiferencia y la frontera eficiente.
Las curvas reciben este nombre porque representan lineas a las cual el inversionista es indiferente al trade-off riesgo/recompensa. Un inversionista quiere un alto rendimiento y riesgo bajo. Frente a las carteras A y B en la Figura, ve a A con bajo rendimiento y bajo riesgo, pero B tiene una mejor recompensa a costa de un mayor riesgo. El inversor es indiferente entre estos dos. Sin embargo, C es mejor que ambos, estando en una curva preferida.
Markowitz en la Práctica
Las entradas al modelo de Markowitz son rendimientos esperados, volatilidades y correlaciones. Con \(N\) activos esto significa \(N + N + N(N-1)/2\) parámetros. La mayoría de estos no se pueden conocer con precisión (¿existen siquiera?); sólo las volatilidades son en absoluto confiable. Habiendo ingresado estos parámetros, debemos optimizar sobre todos los pesos de los activvos en la cartera: Elija un riesgo de cartera y encuentre los pesos que haqcen que el rendimiento de la cartera sea máximo sujeto a esta volatilidad. Este es un proceso que consume mucho tiempo computacionalmente a menos que uno solo tenga una pequeña cantidad de activos.
El problema con la implementación práctica de este modelo lo realizaré enm otro post que publicare posterioremente, usando Python. Por los momentos es importante comprender la lógica del modelo.
Modelo de Precios de Activos de Capital (Capital Asset Pricing Model)
Antes de discutir el modelo de fijación de precios de activos de capital o CAPM debemos introducir la idea del valor \(\beta\). El parámetro \(\beta_i\), de un activo en relación con una cartera \(M\) es la relación de la covarianza entre el rendimiento del valor y el rendimiento de la cartera a la varianza de la cartera. Del siguiente modo
\[ \beta_i = \frac{Cov[R_iR_M]}{Var[R_M]} \]
El Modelo de Indice Unico
Ahora construire un modelo de índices único y describiré las extenciones más adelante. Voy a relacionar el rendimiento de todos los activos al rendimiento de un índice representativo, \(M\). Este índice suele ser tomado como un índice bursátil de amplio rango en el modelo de índice único. Nosotros escribimos el rendimiento del i-ésimo activo como
\[ R_i = \alpha_i + \beta_iR_M + \epsilon_i \]
Usando esta representación podemos ver que el rendimiento de un activo se puede descomponer en tres partes:
Una media constante
Una parte aleatoria común con el índice \(M\) y,
una parte aleatoria no correlacionada con el índice, \(\epsilon_i\).
La parte aleatoria \(\epsilon_i\) es única para el i-ésimo activo, y tiene media cero. Observe cómo todos los activos están relacionados con el índice \(M\) pero son de contrario completamente sin correlación.
En la Figura 7 se muestra un gráfico de rendimiento de las acciones de Walt Disney frente a los rendimientos del S&P 500; \(\alpha\) y \(\beta\) se pueden determinar a partir de un análisis de regresión lineal. Los datos utilizados en este gráfico abarcaron desde enero de 1985 hasta casi finales de 1997.
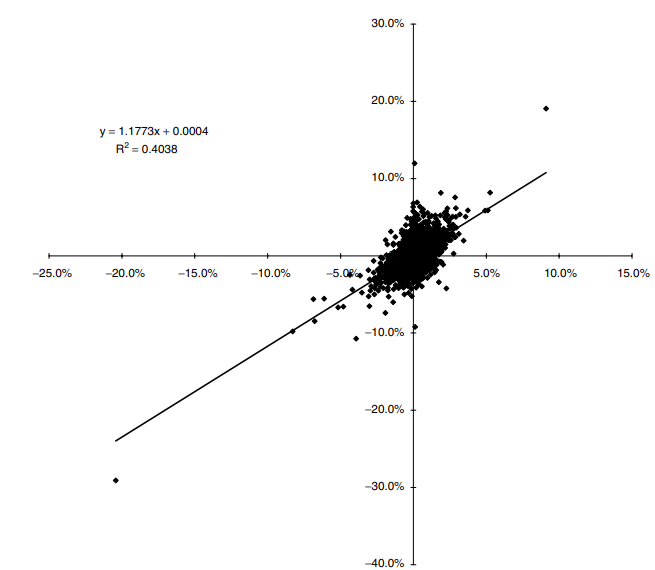
El rendimiento esperado del índice se denotará por \(\mu_M\) y su desviación estándar por \(\sigma_M\). El rendimiento esperado del i-ésimo activo es entonces:
\[ \mu_i = \alpha_i + \beta_i\mu_M \]
y la desviación estandar
\[ \sigma_i = \sqrt{\beta_i^2\sigma_M^2 + e_i^2} \]
donde \(e_i\) es la desviación estándar de \(\epsilon_i\).
Si tenemos una cartera de dichos activos, el rendimiento viene dado por
\[ \begin{eqnarray} \frac{\delta \Pi}{\Pi} = \sum_{i=1}^N W_iR_i = \left(\begin{array}{0}\sum_{i=1}^N W_i\alpha_i\end{array}\right) + R_M\left(\begin{array}{0} \sum_{i=1}^N W_i\beta_i\end{array}\right) + \sum_{i=1}^N W_i\epsilon_i \end{eqnarray} \]
De esto se sigue que
\[ \mu_\Pi = \left(\begin{array}{0}\sum_{i=1}^N W_i\alpha_i\end{array}\right) + E[R_M]\left(\begin{array}{0}\sum_{i=1}^N W_i\beta_i\end{array}\right) \]
Podemos escribir
\[ \alpha_\Pi = \sum_{i=1}^NW_i\alpha_i \hspace{1cm}y \hspace{1cm} \beta_\Pi = \sum_{i=1}^NW_i\beta_i \]
Entonces,
\[ \mu_\Pi = \alpha_\Pi + \beta_\Pi E[R_M] = \alpha_\Pi + \beta_\Pi \mu_M\]
De manera similar, el riesgo se mide por
\[ \sigma_\Pi = \sqrt{\sum_{i=1}^N\sum_{j=1}^N W_iW_j\beta_i\beta_j\sigma_M^2 + \sum_{i=1}^N W_i^2 e_i^2} \]
Si los pesos son casi iguales, \(N^{-1}\), entonces los términos finales dentro de la raíz cuadrada también son \(O(N^{-1})\). Por lo tanto, esta expresión es, al orden principal como \(N \longrightarrow \infty\),
\[ \sigma_\Pi = \left|\begin{array}{0}\sum_{i=1}^N W_i\beta_i\end{array}\right|\sigma_M = \left|\begin{array}{0}\beta_\Pi\end{array}\right|\sigma_M \]
Observe que la contribución de los no correlacionados a la cartera se desvanece a medida que aumentamos le número de activos en la cartera: El riesgo asociado con el \(\epsilon_s\) se llama riesgo diversificable. El riesgo restante, que esta correlacionado con el índice, se denomina riesgo sistematico.
Elegir la Cartera Optima
El principal es el mismo que el modelo de Markowitz para la elección óptima de cartera. La diferencia es que hay muchos menos parámetros para ingresar, y el cálculo es mucho más rapido.
El procedimiento es el siguiente. Elija un valor para el rendimiento de la cartera \(\mu_\Pi\). Sujeto a esta restricción, minimizar \(\sigma_\Pi\). Repita esta minimización para diferentes rendimientos de carteera para obtener la frontera eficiente. La posición es esta curva es entonces una elección subjetiva.
Medición del Desempeño
Si uno ha seguido una de las estratetias de asignación de activos, o simplemente ha negociado en instinto, ¿puede uno decir qué tan bien lo ha hecho? ¿Fueron los resultados sobresalientes deido a un extraño instinto natural, o los horribles resultados fueron simplemente mala suerte?
El rendimiento ideal sería uno en el que los rendimientos superaran la tasa libre de riesgo, pero en una moda consistente. No solo es importante obtener un alto rendimiento de la gestión de la cartera, pero uno debe lograr esto con la menor aleatoriedad posible.
Las dos medidas más comunes de rendimiento por unidad de riesgo son
Relación de Sharpe de recompensa a variabilidad y el
índice de Treynor de recompensa a la volatilidad.
Estos se definen como
\[ \begin{eqnarray} ratio Sharpe &=& \frac{\mu_\Pi - r}{\sigma_\Pi}\\[0.2cm] ratio Treynor &=& \frac{\mu_\Pi - r}{\beta_\Pi} \end{eqnarray} \]
En estos \(\mu\) y \(\sigma\) son el rendimiento realizado y la desviación estándar de la cartera durante el período. El \(\beta\) es una medida de la volatilidad de la cartera. El ratio de Sharpe generalmente se usa cuando la cartera es la totalidad de la inversión de uno y el ratio de Treynor cuando se examina el rendimiento de un componente de la cartera de toda la empresa, digamos.
Cuando la cartera baja las dos medidas son las mismas (hasta un factor del mercado Desviación Estándar)
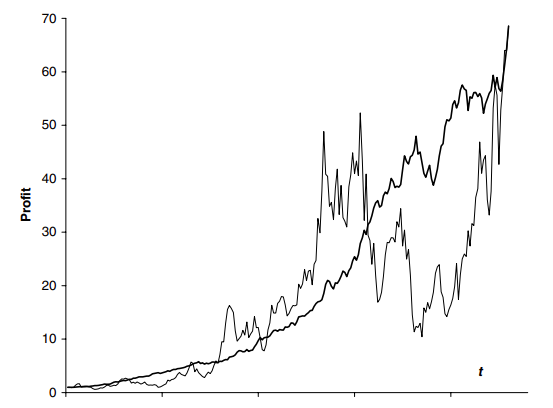
La Figura 8 muestra el valor de la cartera frente al tiempo para un buen administrador y un mal administrador.
Resumen
La gestión de carteras y la asignación de activos consisten en asumir riesgos a cambio de una recompensa.
Las preguntas son, ¿como decidir cuánto riesgo tomar? ¿cómo obtener el mejor rendimiento? Pero la teoría de los derivados se basa en no correr ningún riesgo en absoluto, por lo que he dedicado tiempo a gestión de cartera en este post.
Existe tanta incertidumbre en el tema de las finanzas que la eliminación del riesgo es casi imposible y las ideas detrás de la gestión de carteras deben ser apreciadas por cualquier persona involucrada en derivados.
Valor en Riesgo (Value at Risk)
Definición
El valor en riesgo es una estimación, con un cierto grado de confianza, de cuánto se puede perder de la cartera, en un horizonte de tiempo dado.
El grado de confianza normalmente se establece en 95%, 87.5%, 99%, etc. El horizonte temporal de interés puede ser de un día, por ejemplo, para actividades comerciales o de meses para gestión de cartera.
Como ejemplo de VaR, podemos calcular (mediane los métodos que e describirán aquí) que durante la próxima semana hay un 95% de probabilidad de que no perdamos más de $10 millones. Podemos escribir esto como
\[ Prob\{\delta V \leq -\$10 m\} = 0.05 \]
donde \(\delta V\) es el cambio en el valor de la cartera. (uso \(\delta\) para “el cambio en” para enfatizar que estamos considerando cambios en un tiempo finito.) En símbolos, esto es
\[ Prob\{\delta V \leq -VaR\}= 1- c \]
donde el grado de confianza es \(c\).
El VaR se calcula asumiendo circustancias de mercado normales, lo que significa que el mercado extremo no se consideran condiciones como choques, o se examinan por separado. Así, efectivamente, el VaR mide lo que se puede esperar que suceda durante la operación diaria de una institución.
Para el computo del VaR requerimos disponer al menos de los siguientes datos:
Los precios vigentes de todos los activos en cartera y,
sus volatilidadesa y correlaciones entre ellos
Si los bienes son negociados podemos tomar los precios del mercado (marking to market).
Por lo general, se supone que el movimiento de los componentes de la cartera son aleatorias y extraídas de distribuciones normales.
VaR para un único activo
Empecemos por estimar el VaR de una cartera compuesta por un único activo.
Supongamos que tenemos una cantidad de una acción con precio \(S\) y volatilidad \(\sigma\). Queremos saber con el 99% de confianza cuál es el máximo que podemos perder durante la próxima semana, estoy usando notación deliberadamente similar al del mundo de los derivados
\[ \sigma S\left(\begin{array}{0}\frac{1}{52}\end{array}\right)^{1/2} \]
ya que el paso de tiempo es \(1/52\) de un año. Finalmente, debemos calcular la posición de la cola extrema izquierda de esta distribución correspondiente a
\[ 1\% = 100 - 99\% \]
Solo necesitamos hacer esto para la distribución normal estandarizada, porque podemos llegar a cualquier otra distribución escalando. En la siguiente tabla, vemos que el intervalo de confianza del 99% corresponde a 2.33 desviaciones estándar de la media.
| Grado de Confianza (%) | Número de desviaciones estándar de la media |
|---|---|
| 99 | 2.326342 |
| 98 | 2.053748 |
| 97 | 1.88079 |
| 96 | 1.750686 |
| 95 | 1.644853 |
| 90 | 1.281551 |
Dado que tenemos una cantidad de acciones, el VaR es dado por
\[ 2.33\sigma\triangle S(1/52)^{1/2} \]
De manera general, si el horizonte de tiempo es \(\delta t\) y el grado de confianza es \(c\), tenemos
\[ VaR = -\sigma \triangle S(\delta t)^{1/2}\alpha(1-c) \]
donde \(\alpha(.)\) es la función de distribución acumulativa inverdsa para la distribución Normal estandarizada, que se muestra en la Figura 9,
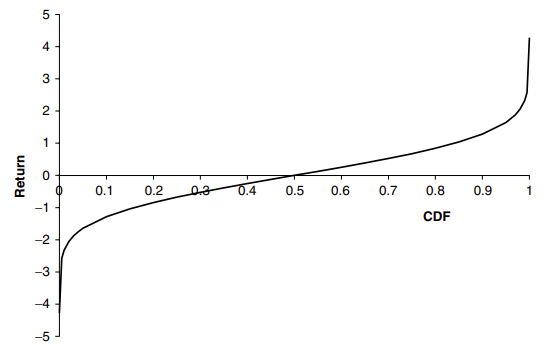
En la Figura 10 hemos supuesto que el rendimiento del activo se distribuye normalmente con una media cero. La suposición de media cero es válida para horizontes temporales cortos: La desviación estándar del rendimiento escala con la raíz cuadrada del tiempo pero la media escala con el tiempo mismo.
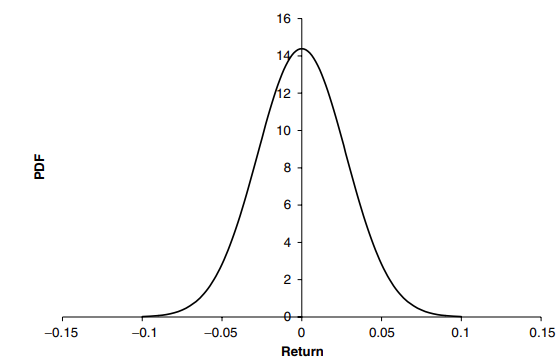
Para horizontes a más largo plazo, el rendimiento se desplaza hacia la derecha (es de esperar) en una cantidad proporcional al horizonte de tiempo. Por lo tanto, para escalas de tiempo más largas, la ecuación anterior debe modificarse para tener en cuenta el derivado del valor del activo. Si la tasa de este derivado es \(\mu\) entonces la ecuación anterior se convierte en
\[ VaR = \triangle S(\mu \delta t - \sigma \delta t^{1/2} \alpha(1-c)) \]
VaR para un Portafolio o Cartera
Si conocemos las volatilidades de todos los activos de nuestra cartera y las correlaciones entre ellos entonces podemos calcular el VaR para toda la cartera.
Si la volatilidad del i-ésimo activo es \(\sigma_i\) y la correlación entre el i-ésimo y el j-ésimo activo es \(\rho_{ij}\) (con \(\rho_{ii} = 1\)), entonces el VaR para la cartera compuesta por M activos con una participación de i del i-ésimo activo es
\[ -\alpha(1-c)\delta t^{1/2}\sqrt{\sum_{j=1}^M\sum_{i=1}^M \triangle_i\triangle_j\sigma_i\sigma_j\rho_{ij}S_iS_j} \]
Uso del VaR como medida de rendimiento
Uno de los usos del VaR en la medición del desempeño de bancos, mesas o comerciantes. En el pasado, el “talento comercial” se ha medido únicamente en términos de ganancias; la bonificación de un comerciante esta relacionado con esa ganancia. Esto anima a los comerciante a asumir riesgos; piensa en lanzar una moneda al aire y recibes un porcentaje de la ganancia pero sin la desventaja (que se lleva el banco), ¿cuánto apostarías? Una mejor medida del talento comercial podría tener en cuenta el riesgo en tal apuesta, y premiar una buena relación rendimiento-roesgo. El ratio
\[ \frac{\mbox{Retorno superior al libre de riesgo}}{volatilidad} = \frac{\mu - r}{\sigma} \]
La relación de Sharpe, es una medida de este tipo. Alternativamente, use VaR como la medida de riesgo y ganancia/pérdida como medida de rendimiento.
\[ \frac{\mbox{Perdidads y ganancias diarias}}{\mbox{VaR diaria}} \]